Analizing the Quoted Product Data after Stramlining The Process
Utilizing Python and Jupyter Notebooks in VS Code
No 1 Project Links:
No 2 Gathering the Data
Five and a half years has passed since we put the calculator into production...
The first step in this process, was to gather all of the information that was generated by the tool and begin organizing it for cleaning and exploration. As the tool was created in Microsoft Access, it was easy enough to export the tables of data as excel spreadsheets and save them into a repository. I set up a Github repository in order to track the progress of the project and allow for version control.
Click Here to Visit the Repo: OHMS Data Analysis Capstone
No 3 Cleaning the Data
While I could use Excel for the analysis of this data I need to show some level of competence in some of the other tools used for completing this task.
The documentation of the step-by-step cleaning process is going to need to be recreated at a later time. The process I used started with removing records that contained installation service lines. I descovered that I needed to fill in the Manufacturer information. This was supposed to be part of the quote process however, it had been skipped by the Operations Manager to save time. I therefore relied on my industry knowledge in order to fill in this missing information. I then joined the Date information that was captured in the Operations worksheet table utilizing the unique quote numbers to assure that the dates matched the quotes. The next version of the tool will need to have the select Manufacturer process automated. Following these cleaning steps, I made the decision to complete the remainder of the transformation and analysis of the data in Jupyter Notebooks for project documentation and my own education of Python for Data Analysis.
No 4 Analyzing the Data
Let's keep this basic and by the numbers. I will update this page as I continue to analize this data set.
The environment needed to be setup and documented. I am using Anaconda for my version of Python and I created a Virtual Environment in order to maintain the integrety of the project. I documented the versions of the software in the project ReadMe.txt file.
For the IDE, I am using VS Code with Jupyter Notebooks and then I will move the code to a regular python file. I am doing this to show the ability to flex between the various ways of completing the same task. And, this seems to be the two standards for general Exploration and Data Analysis. The details of the analysis are available at my repository so, I will keep to a broader narative in regards to my findings.
Looking at the data as it is initally presented I decidied that finding the distribution of the various Product catagories would lend some insight as to where the majaority of the product that was quoted existed.
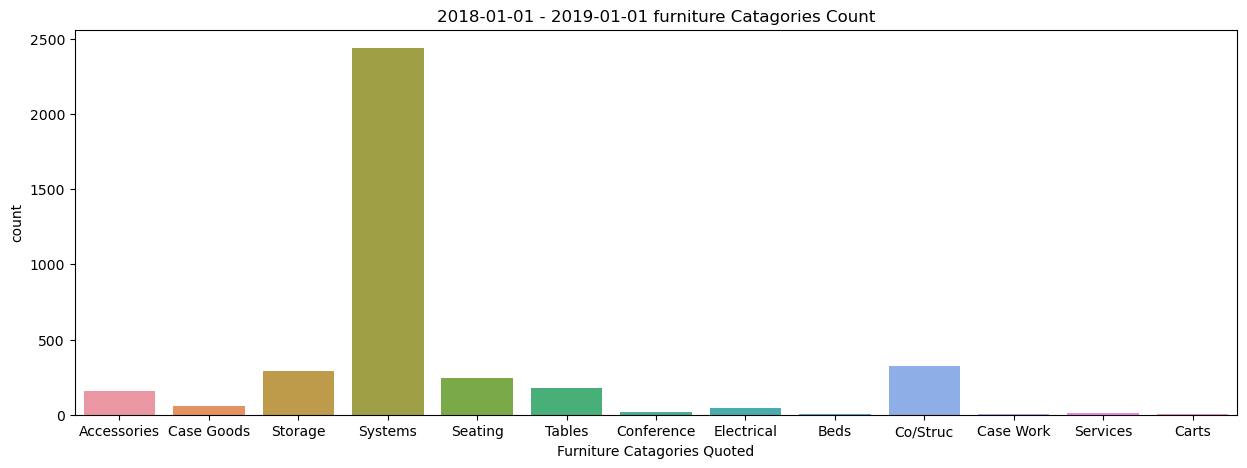
The results were about what I had expected. With systems furniture being the larger portion of the product quoted. Next I wanted to look at the bearkdown of the systems furniture and find which part catagories were the most frequently specified.
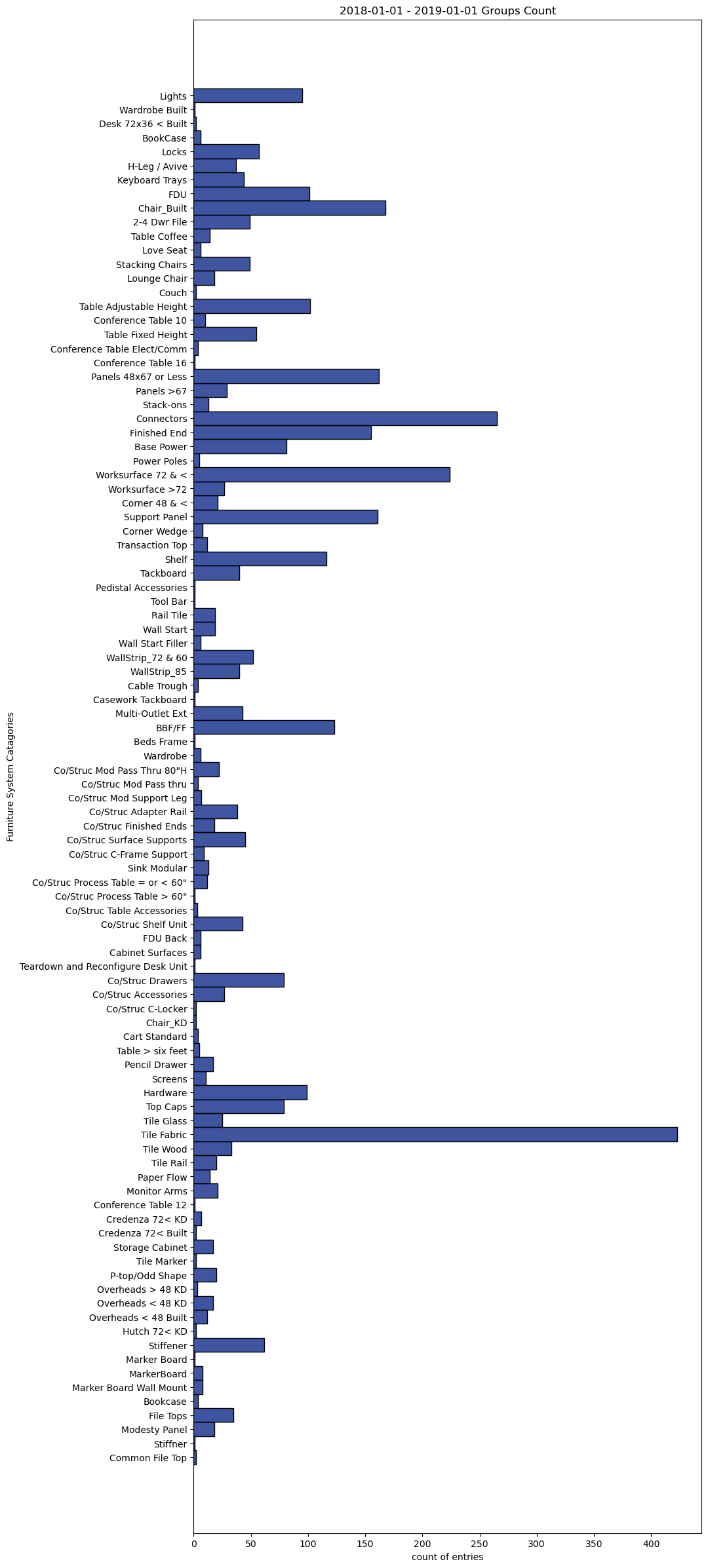
The fact that Fabric Tiles were the most specified part was not suprising. What was suprising, was the amount of support panels that had been quoted. The quoted lines were very close to the amount of lines for panels 67" high and less. I wouldn't have expected that result.
The next item I wanted to look at in this section was what manufacturers were quoted most often.
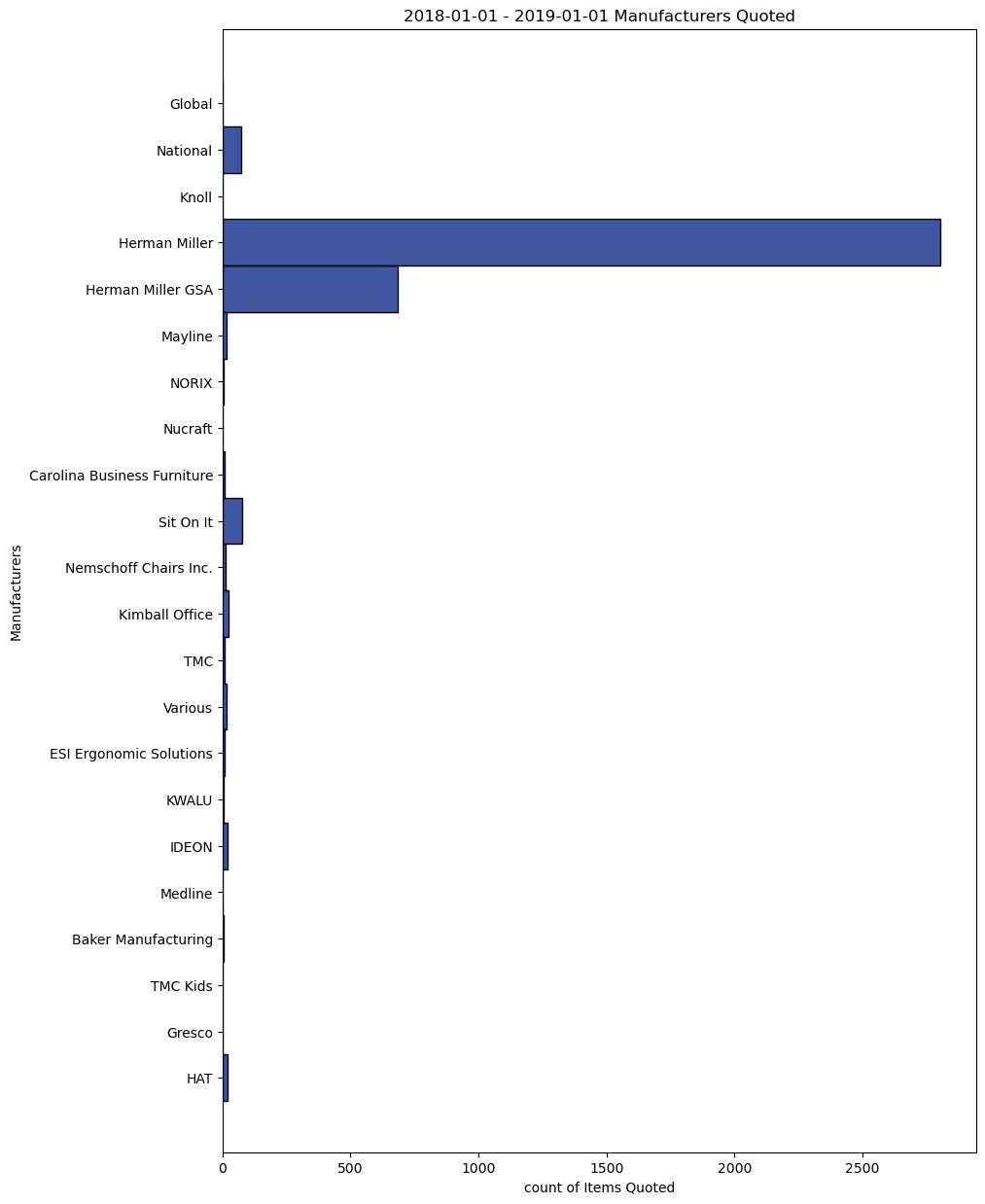
There is no suprise here, This is a Herman Miller Dealership and they have done well promoting there main furniture line. Showing well in the mix is Sit-on-it and National seating. I was suprised to see that the National seating was quoted more often than IDEON. This is due to the fact that IDEON was normally specified for the larger waiting areas.
The last item that I was curious about was the quantity distribution of line items. in order to understand if the previous graphs would be skewed if I were to look at them as the sum of there quantities instead of the number of line entries. To do this, I looked at the distribution quantity per entry and, here is what was returned.
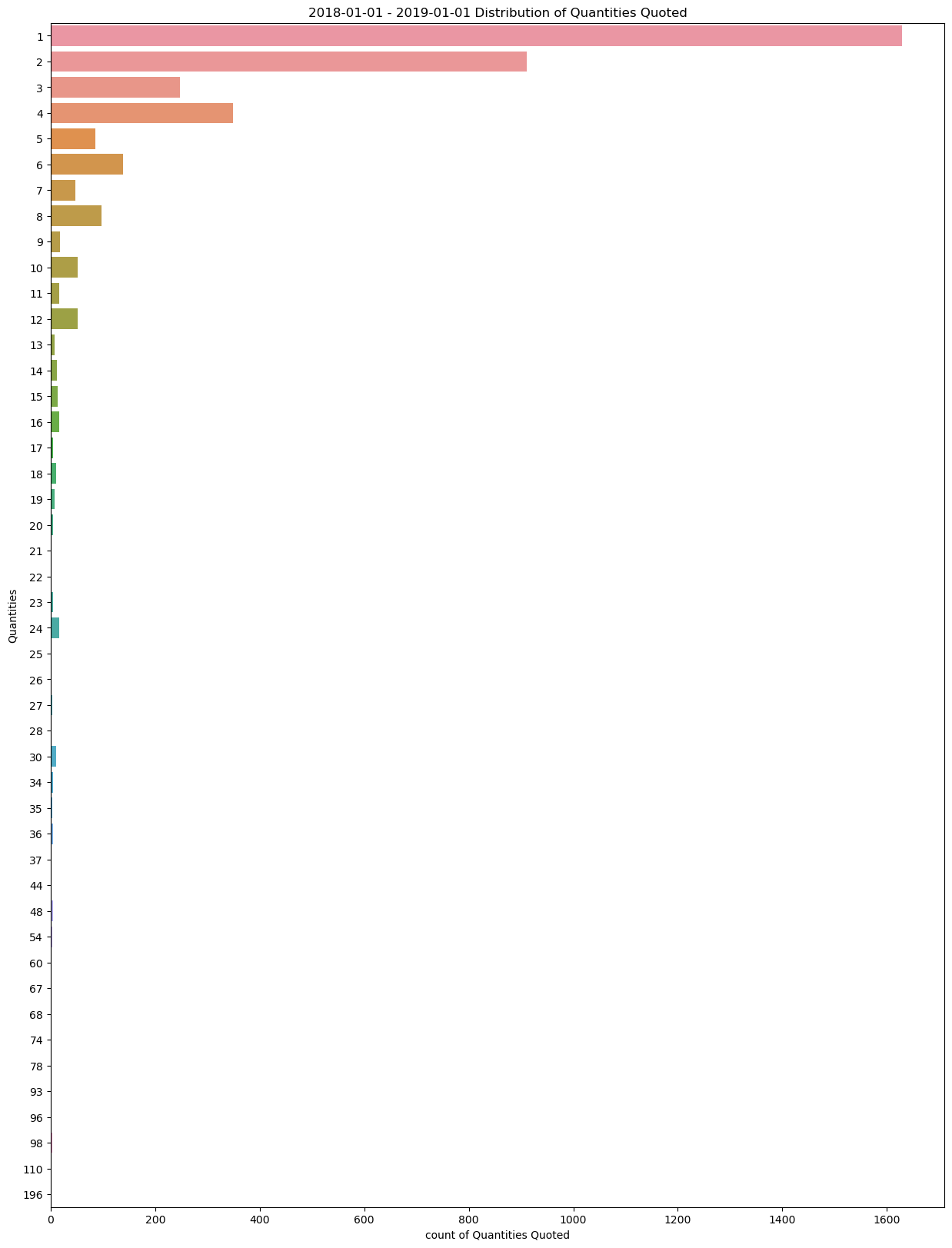
I think that this needs a deeper look to determin what was being specified with a quantity of 196. That is a definate outlier. As it turns out, This was a single line representing a single partnumber for a mobile isle filing system. The part is represented correctly in the previous graphs.
No 5 Tools
- MS Excel
- Jupyter Notebook
- VS Code
- Github
- Python (Anaconda)
- Pandas
- numpy
- matplotlib
- Seaborn